Лекция № 10. «Учет влияния транзакций»
Одной из основных целей настоящей лекции является формирование навыков решения следующей профессиональной задачи проектирования баз данных этапа создания физической модели базы данных: учета влияния транзакций.
Решая задачу создания первой итерации физической модели базы данных, проектировщики базы данных преследовали достижение следующих целей:
· удовлетворить потребности в хранении данных предметной области в рамках реляционной модели данных, т.е. были созданы базовые таблицы для хранения информации обо всех сущностях предметной области;
· удовлетворить требования целостности данных, т.е. были определены типы колонок и наложены ограничения на значения колонок базовых таблиц, которые следовали бизнес-правилам предметной области;
· удовлетворить требования ссылочной целостности, т.е. в случае принятия решения о поддержке ссылочной целостности встроенными средствами СУБД были наложены ограничения ссылочной целостности на таблицы, исходя из бизнес-правил ссылочной целостности предметной области;
· частично удовлетворить требования независимости представления данных для конечного пользователя от характера физического хранения данных, т.е. была построена первая итерация внешней схемы.
Вторая главная цель физического проектирования реляционной базы данных состоит в том, чтобы дать гарантию того, что база данных обеспечивает требуемый уровень производительности. Таким образом, следующей профессиональной задачей проектировщика базы данных является борьба за производительность базы данных, т.е. удовлетворение требований по обеспечению требуемого уровня производительности базы данных. Обычно производительность базы данных измеряется в терминах производительности транзакций (transaction performance).
На предыдущем этапе проектировщик реляционной базы данных решил первую главную задачу физического проектирования - в рамках требований реляционной модели создал объекты хранения данных. Он отобразил сущности и взаимосвязи логической модели реляционной базы данных в физические объекты СУБД - таблицы, индексы, представления. Критерием этой работы проектировщика базы данных выступает удовлетворение требований по производительности транзакций. Решающим фактором для проектировщика базы данных в борьбе за производительность является решение задачи выбора между физическими конструкциями СУБД, которые могут быть использованы для повышения производительности транзакций.
Чтобы успешно решить данную задачу, проектировщик базы данных должен иметь хорошо определенные транзакции, которые могут существовать в базе данных. Однако в большинстве практических случаев получить изначально полностью прописанные транзакции к базе данных является весьма сложной организационной задачей. В условиях недостаточных сведений о транзакциях проектировщику приходится зачастую полагаться на свой собственный опыт проектирования, выполнять выборочную настройку полученной первой итерации физической модели базы данных и переадресовывать окончательное решение данной задачи администратору базы данных. К тому же часть проблем, связанная с производительностью базы данных, может быть выявлена лишь на стадии тестирования и опытной эксплуатации базы данных. Совокупность таких отложенных задач проектирования автор называет задачами обратного влияния, которые будут изучаться нами в последних лекциях этого курса.
Отметим, что при решении задач этого этапа нельзя опираться только на знание стандарта SQL, как мы делали это в предыдущей лекции. В действие вступают конструкции конкретной СУБД, выбранной для реализации базы данных. Основными механизмами промышленных СУБД для решения настоящей задачи повышения производительности являются денормализация, индексы, кластеризация и разделение. Индексы, кластеризация и разделение (секционирование на уровне возможностей СУБД) будет рассматриваться в следующей лекции.
Определение транзакций базы данных
Понимание типа приложений базы данных
Прежде чем обсуждать основные типы приложений баз данных, уточним термины транзакция и запрос. В теории баз данных, вообще говоря, под транзакцией понимают одну из команд SQL - SELECT, INSERT, UPDATE, DELETE. Однако в зависимости от типа приложений термин транзакция трактуется более свободно как элементарная логически завершенная единица работы (так называемая бизнес-транзакция), которая может включать несколько команд вставки, удаления или модификации. В зависимости от того, какие команды SQL используются, транзакции разделяют на транзакции только для записи (write-only), только для модификации (modify-only), только для чтения (read-only), только для удаления (delete-only). Транзакции только для чтения называют запросом.
Исходя из такого деления транзакций по типам обработки с учетом частоты транзакций каждого типа, можно выделить три основных классических типа приложений баз данных:
· OLTP-системы (On-Line Transaction Processing). OLTP-система - это такое приложение, которое содержит в основном транзакции вставки, обновления и удаления, с высокой частотой преимущественно транзакций обновления. Классическим примером этих систем являются системы резервирования авиабилетов или обслуживания гостиниц. Для таких систем характерен высокий уровень параллелизма (high concurrency), который в данном случае означает, что много пользователей используют базу данных одинаковым образом.
· DSS-системы (Decision Support System). DSS-система - это такое приложение, которое работает с очень большой базой данных в режиме "только чтение". Обычно используется набор фиксированных простых запросов или нерегламентированные запросы пользователей. Хорошим примером такой системы является корпоративная информационная система организации.
· BATCH-системы. BATCH-системы - это такое приложение, которое работает с базой данных в не интерактивном режиме. Обычно оно использует много транзакций вставки, удаления и обновления, имеет низкий уровень параллелизма, что означает небольшое число пользователей, использующих базу данных одинаковым образом. Существенным фактором для этих систем является отношение запросов к транзакциям обновления. Классическим примером таких систем является обслуживание базы данных продукции организации.
Можно выделить еще несколько типов приложений, появившихся в последние два десятилетия.
· OLAP-системы (On-Line Analytical Processing). OLAP-система - это приложение, которое обеспечивает аналитическую обработку данных, включающую математический, статистический или иной анализ данных. Такие системы нельзя отнести полностью либо к OLTP-, либо к DSS-системам. Они располагаются где-то между ними. В рамках OLAP систем выделяют так называемые ROLAP системы (Relational OLAP), т.е. OLAP-системы, использующие реляционные базы данных. Типичные OLAP-системы разрабатываются обычно под многомерные модели данных.
· VCDB-системы (Variable Cardinality Database). VCDB-система - это такое приложение обработки данных, для которого база данных растет или сжимается в размерах периодически в зависимости от характера обработки данных. Обычно размер этих баз данных постоянно растет. Кардинальность относится к числу строк в таблицах базы данных в текущий момент времени. Типичным примером такой системы является база данных по обеспечению безопасности (Security Authorization Database), для которой характерна короткая по времени активность записей в таблицы.
Проектировщик базы данных должен оценить тип приложений, для которых он разрабатывает базу данных. Это позволит ему оценить (в случае отсутствия явно прописанной в документации информации):
· тип транзакций (какие);
· частоту транзакций каждого типа (сколько);
· количество одновременно работающих с базой данных пользователей.
Далее эта информация понадобится проектировщику базы данных для анализа транзакций.
Спецификация транзакций
Итак, транзакция базы данных - это логическая единица работы, которая переводит базу данных из одного завершенного состояния в другое завершенное состояние. Под завершенным состоянием базы данных здесь понимается такое состояние данных в базе данных, которое не нарушает целостности этих данных - все данные в таблицах базы данных правильны, а ссылки между таблицами корректны. В дополнение, транзакция группирует операции над данными таким образом, чтобы все обращения к базе данных были успешно завершены или, в случае сбоя, база данных возвратилась в предыдущее завершенное состояние (откат транзакции).
Поскольку любая операция изменения данных в базе данных несет в себе потенциальную возможность нарушения целостности данных, необходимо строго определять транзакции и идентифицировать информацию, которая обычно включается в определение транзакции.
Определение транзакции может иметь различные формы. Иногда для определения транзакций используется репозиторий данных CASE-средств проектирования базы данных. Очень часто определение транзакций выполняется посредством текстовых описаний. Независимо от выбранного подхода любое хорошее определение транзакции включает несколько важных элементов. К таким элементам относятся:
· имя транзакции;
· номер транзакции;
· описание транзакции;
· характер транзакции и ее сложность;
· объем транзакции;
· требования к производительности транзакции;
· относительный приоритет;
· время выполнения транзакции.
Первым шагом в определении транзакции является уникальная идентификация каждой транзакции базы данных. Это можно сделать назначением имени и номера каждой транзакции базы данных. Имена транзакций должны позволять пользователям отличать их друг от друга. Описание транзакций включает перечень операций предметной области, которые выполняются транзакцией. Что касается описания транзакций, то оно должно быть выполнено в терминах предметной области, понятных пользователю. Здесь нужно иметь в виду следующее: а) описание транзакции должно описывать, что транзакция делает для пользователя, а не как она выполняется; и б) описание должно быть понятно пользователю, что не исключает использование технологического жаргона.
Пример. Спецификация транзакции
Номер транзакции: 001
Имя транзакции: Назначить работу служащему.
В OLTP-системах большинство транзакций известны заранее, поэтому между спецификацией транзакции и транзакцией базы данных существует взаимно однозначное соответствие. В DSS-системах транзакции часто не известны заранее, и, следовательно, невозможно в принципе описать все транзакции. В этом случае спецификация транзакции лишь в общих чертах описывает транзакции базы данных, поэтому проектировщику базы данных важно уметь предсказать тип транзакций, которые пользователь вероятнее всего будет выполнять в базе данных.
Для каждой транзакции может быть определен характер транзакции как онлайновая транзакция или пакетная транзакция, а также указана ее сложность. Обычно сложность указывается в терминах "высокая", "средняя", "низкая". Эта информация нужна проектировщику базы данных для оценки транзакций базы данных в целом. Количество транзакций той или иной сложности влияет на время проектирования физической модели базы данных - чем больше в базе данных транзакций высокой сложности, тем больше время проектирования физической модели. Сложность транзакции является условной мерой трудоемкости работы проектировщика базы данных при достижении требований производительности базы данных.
Высокая сложность приписывается обычно транзакции, которая имеет две из следующих характеристик:
· содержит от 8 до 10 команд SQL;
· содержит предложение WHERE с большим количеством предикатов;
· содержит предложение WHERE с более чем тремя соединениями или под запросами;
· обрабатывает более чем 100 строк.
Низкая сложность приписывается транзакции со следующими характеристиками:
· содержит до трех команд SQL;
· содержит предложение WHERE с одним или двумя предикатами;
· обрабатывает менее чем 25 строк.
Транзакция со средней сложностью имеет характеристики между нижней и высокой сложностью.
Пример. Спецификация транзакции
Продолжая приведенный выше пример, можем указать следующее:
Характер транзакции: онлайновая транзакция.
Сложность: средняя.
Объем транзакции (Transaction volume statistics) включает обычно два параметра: среднюю частоту транзакции (например, 50 тр./ч) и пиковую частоту транзакции (например, 70 тр./ч). Оценка частотных характеристик транзакций базы данных очень важна для проектирования физической модели базы данных: настройка физической структуры базы данных для транзакций с высокой частотой существенно отличается от настройки ее для транзакции с низкой частотой использования.
Для модернизации существующих систем информация о частотах транзакций может быть представлена во входной документации на основе анализа статистики эксплуатации системы. А вот для вновь создаваемых баз данных такую информацию получить практически невозможно, и приходится пользоваться приблизительными оценками.
Пример. Дополняя наш пример, мы можем указать, чтоСредняя частота транзакции: до 10 в день.Пиковая частота: 10 в час.Спецификация транзакции должна включать требования по производительности транзакции. Производительность базы данных в целом складывается из производительности каждой транзакции в отдельности и их распределения во времени. Это очень важная информация для проектировщика данных при решении им задачи настройки физической структуры базы данных. Если проектировщик базы данных не имеет такой информации, он не может решить задачу достижения производительности путем подбора соответствующих конструкций базы данных. Требования по производительности обычно задаются в виде параметра время реакции, т.е. количества секунд, требуемых для выполнения транзакции. Например, во многих банковских системах транзакция для снятия денег со счета клиента не должна занимать более 5 секунд.
Другой формой задания требования на производительность транзакций базы данных является указание их характера и сложности. Например:
· онлайновые транзакции высокой сложности должны выполняться не более 15 с;
· онлайновые транзакции средней сложности должны выполняться не более 7 с;
· онлайновые транзакции низкой сложности должны выполняться не более 4 с;
· пакетные транзакции высокой сложности должны выполняться не более 1 часа;
· пакетные транзакции средней сложности должны выполняться не более 0,5 часа;
· пакетные транзакции низкой сложности должны выполняться не более 15 мин.
В какой форме проектировщик базы данных получит требования на производительность транзакций, сказать сложно. Будет очень хорошо, если он их вообще получит. Это является одним из самых узких мест, как в исходной документации, так и в проектировании физической модели. На практике проектировщики баз данных "отпускают" базу данных в опытную эксплуатацию таким образом, чтобы получить временные характеристики выполнения транзакций и удовлетворить требованиям по производительности в рамках решения задач обратного влияния.
Желательно в спецификации транзакции указать ее относительный приоритет, который показывает, насколько важна настоящая транзакция для предметной области по сравнению с другими. Относительный приоритет транзакции позволяет проектировщику базы данных сгруппировать транзакции по этому параметру, что даст возможность последовательно оценить все транзакции базы данных и их вклад в производительность базы данных.
Далее в процессе создания физической модели данных проектировщик базы данных будет настраивать физическую структуру так, чтобы каждая в отдельности выполнялась быстрее. Выполнение какой-либо транзакции в базе данных с большим приоритетом отрицательно сказывается на производительности других транзакций. Ранжирование транзакций по относительному приоритету позволяет сбалансировать влияние транзакций друг на друга в базе данных в целом.
Задание приоритета транзакций может иметь различные формы. Обычно такое действие сводится к субъективной оценке в виде числа от 1 до 10.
Каждая спецификация транзакции должна содержать команды SQL, которые задают операции с базой данных. Указание команд SQL в контексте создания физической модели базы данных позволяют оценить время выполнения транзакций (execution time), т.е. фактическое количество секунд, необходимое для завершения транзакции в режиме эксплуатации базы данных. Для проектировщика базы данных этот параметр важен еще и с точки зрения разработки спецификаций модулей приложений базы данных для разработчиков приложений.
Помимо собственно команды языка манипулирования данными, желательно включить некоторый комментарий к каждой команде, в котором указать: а) что команда делает, б) почему это требуется, и в) количество строк в базе данных, которое захватывается командой. Время выполнения команды SQL непосредственно зависит от числа обрабатываемых командой строк. Обычно время выполнения транзакций можно оценить на стадии опытной эксплуатации и тестирования базы данных.
Пример. Продолжая наш пример, можно составить следующую таблицу.
Таблица 10.1. Описание результатов выполнения транзакции | |
|
Команда |
Комментарии |
|
Select works from project where empno=:1 and works=:2 |
Возвращает информацию о назначении данной работы данному служащему. По крайней мере, одна строка возвращается. Число строк, которые могут обрабатываться командой, равно текущему размеру таблицы PROJECT |
|
Select works from project where empno=:1 |
Возвращает список работ данного служащего, чтобы оценить его загруженность. Число строк, которые могут обрабатываться командой, равно текущему размеру таблицы PROJECT |
|
Insert into project empno, works values(:1,:2) |
Назначает данного служащего на данную работу, если это необходимо |
Составив описание транзакций, проектировщик базы данных готов, в зависимости от полноты и достоверности собранной информации, принимать или откладывать решение об изменении внутренней схемы базы данных с целью достижения требований по производительности базы данных. Механизмы, с помощью которых проектировщик базы данных может обеспечить требования производительности, описываются в следующих разделах настоящей лекции в предположении, что выбрана СУБД Oracle 9i.
Денормализация
Понятие о денормализации
Начиная с этого раздела мы переходим к рассмотрению методик настройки физической структуры реляционной базы данных с целью удовлетворения требования к производительности базы данных. Эти методики представляют собой набор рекомендаций и эвристических правил по изменению физической структуры базы данных, которая была получена проектировщиком базы данных в результате создания первой итерации физической модели базы данных. Ясно, что использование этих методик носит опциональный характер.
В этом разделе будут описаны различные типы денормализации и методы реализации этого процесса. Кроме того, мы рассмотрим, как использовать для поддержки денормализации триггеры и как обеспечить целостность данных, не прибегая к созданию дополнительного кода.
Под денормализацией понимают процесс достижения компромиссов в нормализованных таблицах посредством намеренного введения избыточности в целях увеличения производительности.
В большинстве случаев необходимость денормализации становится очевидной лишь на этапе проектирования модуля. Другими словами, обычно нельзя принять решение о денормализации на основании одной только модели данных. Когда проектировщик принимает решение о денормализации, то должен господствовать здравый смысл. Обычно стараются найти в приложении базы данных критичные процессы и принимать решения о денормализации в основном в пользу этих процессов. Критичные процессы обычно определяют по высокой частоте, большому объему, высокой изменчивости или явному приоритету. Если проектировщик базы данных прописал все транзакции базы данных, то он, вероятно, сможет определить наличие таких критических процессов.
Замечание. Использовать денормализацию только для упрощения SQL-запросов при обращении к базе данных является неправильным решением. Если вы хотите упростить SQL-запросы на уровне приложения или пользователя, то, наверное, лучше использовать представления, а не вводить избыточность. Чтобы повысить производительность запроса, можно ввести индексы. Как оптимизировать запрос, будет рассмотрено в последней лекции этого курса.
Как правило, денормализация уменьшает время запроса за счет DML-операций. Денормализацию следует рассматривать как расширение нормализованной модели данных, которое повысит производительность запросов. При принятии решения о денормализации определите, что является наиболее важным для приложения - избыточность данных или высокая производительность. Если проектировщик базы данных ведет журнал проектирования (некоторый внутренний документ произвольной формы, в котором фиксируются все принятые в процессе проектирования базы данных решения), то в него необходимо занести обоснованное решение о денормализации. Помните, что кроме денормализации существуют и другие пути повышения производительности. Денормализацию таблиц можно выполнять как на уровне логической модели данных, так и на уровне физической модели.
Нисходящая денормализация
Рассмотрим принципы денормализации на уровне логической модели реляционной базы данных. Нисходящая денормализация предлагает перенос атрибута из одной (родительской) сущности в подчиненную (дочернюю) сущность. Из рисунков 9.1 и 9.2 видно, что в денормализованной логической модели мы переместили фамилию клиента из сущности Customer (Клиент) в сущность Order (Заказ). Что дает введение избыточности (перенос атрибута) в данном случае? Единственный выигрыш заключается в том, что мы исключаем операцию соединения, если захотим вместе с заказом увидеть фамилию клиента.
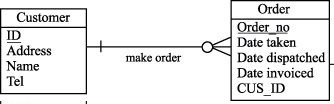
Рис. 9.1. Сущности Customer и Order до денормализации
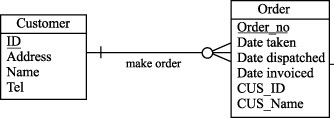
Рис. 9.2. Сущности Customer и Order после денормализации
Таким образом, нисходящая денормализация - это процесс введения избыточных колонок в подчиненных таблицах с целью устранения операций соединения.
Однако устранение соединений посредством нисходящей денормализации редко оправдывает затраты на сопровождение дублирующей колонки в таблице ORDER. Такие соединения, как правило, не являются глобальной проблемой, а выполнение нисходящей денормализации может привести к возникновению дорогостоящих каскадных обновлений, дающих небольшую реальную выгоду. Например, если клиент меняет фамилию, то нам приходится обновлять все заказы, чтобы отразить это изменение. А нужно ли это делать? Следует ли обновлять старые заказы, которые выполнены или закрыты? Если бы не была проведена денормализация, то эти вопросы никогда бы и не возникли.
Нисходящая денормализация оправдана лишь в приложениях, где необходимо устранять операции соединения таблиц. Это имеет место в базах данных большого объема, таких как хранилища данных. При этом проблемы с каскадными обновлениями не возникает потому, что данные в хранилищах данных - архивные.
Восходящая денормализация
Восходящая денормализация предлагает перенос атрибута из подчиненной (дочерней) сущности в родительскую сущность, обычно в форме итоговых данных. На рисунках 9.3 и 9.4 показано, как это можно сделать для сущностей Order и Order Item (Позиция заказа).
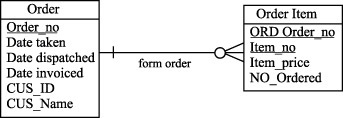
Рис. 9.3. Сущности Customer и Order до денормализации
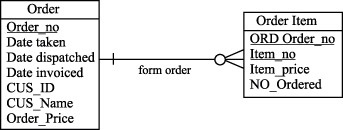
Рис. 9.4. Сущности Customer и Order после денормализации
Например, если в вычисление общей суммы заказа в системы обработки заказов (суммирование колонок Item_Price в таблице Order Item) приводит к снижению производительности, то мы можем повысить производительность этой операции, поместив сумму заказа в избыточном столбце таблицы ORDER. В нашем примере в избыточном столбце хранится сумма значений, но эти приемы применимы к максимальным, минимальным и средним значениям, а также к другим агрегатным показателям.
Таким образом, восходящая денормализация - это процесс введения избыточных колонок в родительских таблицах с целью устранения операций соединения с операциями агрегирования.
Чтобы представить последствия введения денормализации, рассмотрим процедуру сопровождения денормализованных таблиц Order и Order Item, которые сводятся к поддержке следующих бизнес-правил:
· Когда в таблицу Order Item добавляется новая строка, то цена заказа (колонка Order_Price) в таблице Order увеличивается на цену новой позиции заказа (Item_Price).
· Когда строка удаляется из таблицы Order Item, то цена заказа в таблице Order уменьшается на цену старой позиции заказа (Item_Price).
· Когда изменяется цена в таблице Order Item, то цена заказа в таблице Order должна быть откорректирована на разницу между старой и новой ценами позиции заказа (Item_Price).
Поддержка перечисленных выше бизнес-правил создает дополнительную нагрузку на процессы, выполняющие DML-операции в таблице Order Item. Это и есть цена, которую мы вынуждены заплатить за повышение производительности запросов.
Внутритабличная денормализация
Внутритабличная денормализация выполняется в пределах одной таблицы, т.е. это процесс введения избыточных колонок в одной таблице с целью увеличения производительности запроса строки по производному значению. Например, если строка содержит две числовых колонки, X и Y, то значение Z, равное произведению X и Y (Z = X*Y), легко вычислить во время выполнения. Однако предположим, что есть запросы, в которых необходимо осуществить поиск по Z (например, Z принадлежит диапазону от 10 до 20). Сохранив избыточные значения Z в столбце, можно построить индекс по Z, и запросы будут использовать этот индекс. Если индекс по Z строить не надо, то решение о его хранении в отдельном столбце зависит от того, что является более приемлемым - увеличение времени загрузки, вызванное необ ходимостью постоянно пересчитывать Z, или увеличение времени сканирования, обусловленное удлинением строк таблицы за счет хранения дополнительной колонки.
Приведем еще один часто встречающийся пример внутритабличной нормализации. Допустим, что одинаковый текст хранится в двух видах: с символами в верхнем и в нижнем регистре - для отображения и ввода данных с символами в верхнем регистре. Это бывает необходимо для обеспечения работы ускоренных запросов без учета регистра.
Примечание. Обеспечить приемлемую производительность для таблиц умеренного размера (до 10000 строк) в последнем случае можно и без внутритабличной деномализации, переработав запрос с использованием встроенной функции UPPER.
Денормализация методом "разделяй и властвуй"
Денормализация методом "разделяй и властвуй" - это процесс разбиения нормализованной таблицы на две и более таблиц и создание между ними отношения "один к одному" с целью устранения дополнительных операций ввода/вывода или по техническим причинам.
Использование этого приема носит причины технического характера. Во многих СУБД таблица не может иметь больше одного столбца типа LONG или LONG RAW. Допустим, что у вас есть таблица Films и нужно сохранить и окончательный вариант фильма (LONG), и вариант, который отсняли с множеством дублей (LONG RAW). Из-за вышеупомянутого ограничения в одной таблице это сделать нельзя, поэтому один из кодов нужно разместить в отдельной таблице. Проектировщику базы данных не остается ничего другого как разбить таблицу на две.
Иногда лучше вынести столбец LONG в отдельную таблицу, даже если вышеупомянутое ограничение не действует. Рассмотрим таблицу, строки которой содержат в начале ключевые колонки, потом неключевые колонки, а в конце - колонку типа LONG. Предположим, что в большинстве строк столбец LONG содержит данные. Если нет индексов по неключевым столбцам, то при выполнении запросов по любому из этих столбцов СУБД обычно будет осуществлять полное сканирование таблицы. При этом из-за наличия в таблице столбца LONG понадобятся дополнительные операции ввода/вывода.
Чтобы устранить эту проблему, разделите таблицу так, как показано на рис. 9.5.

Рис. 9.5. Выделение колонки LONG в отдельную таблицу
Во многих СУБД таблица не может иметь более 254 столбцов, и если предложить таблицу с большим числом столбцов, то также возникнет причина для разделения такой таблицы на две. Обычно такие таблицы могут понадобиться только в следующих случаях:
· приложение полностью проектируется на базе унаследованной системы, и каждая таблица строится как точная копия файла унаследованной системы. При этом наследуется и структура, и все реляционные свойства в ней отсутствуют;
· выполняется слияние двух таблиц путем формирования в одной из них повторяющейся группы;
· речь идет о хранилище данных, в котором принято решение выполнить массовую нисходящую денормализацию. В этом случае следует создавать таблицы с максимальным для СУБД числом столбцов, так как любое другое решение, вероятно, обусловит необходимость массовых соединений "один к одному".
Согласно мнению известного специалиста в области проектирования реляционных баз данных Д. Энсора, "Хорошей мерой степени нормализации является число столбцов на таблицу. Эмпирическое правило гласит, что очень немногие первичные ключи имеют более двадцати действительно зависимых от них атрибутов".
Денормализация методом слияния таблиц
Денормализация методом слияния таблиц - это процесс объединения одной или более нормализованных таблиц с целью устранения операций соединений или уменьшения в некоторых случаях числа операций вставки.
Возникает резонный вопрос: после того как мы вложили столько сил в нормализацию структур данных и разбивку сущностей, нам предлагается начать слияние таблиц? Фактически слияние оправдано в очень немногих случаях.
Один из примеров обоснованного применения слияния - наличие повторяющейся группы, которая гарантированно состоит из фиксированного числа элементов. Хорошими кандидатами на такое объединение являются таблицы со строкой для каждого месяца года или каждого дня недели. Единственный случай, где фиксированные группы надежны, - это когда они соответствуют абсолютно постоянным вещам, например дням недели.
Будет ли какое либо преимущество от такого слияния заранее сказать трудно. Подход к денормализации должен определяться требованиями к обработке данных.
Альтернатива данному способу денормализации - физическое размещение таблиц в кластере (например, как в СУБД Oracle). Это позволяет хранить рядом строки логически связанных отдельных таблиц.
Таким образом, на практике денормализация представляет собой набор приемов преобразования таблиц с целью повышения производительности обработки запросов. С точки зрения реляционной теории мы как бы не принимаем в рассмотрение наличие некоторых функциональных зависимостей в таблицах. Основным критерием проведения денормализации нормализованных таблиц являются требования к обработке данных. В реляционных базах данных следует избегать неоправданной денормализации таблиц.
Методы реализации денормализации: Разбиение таблиц базы данных
Разбиение (splitting) таблиц является одним из общих методов денормализации, который применяется в физическом проектировании реляционных баз данных. Разбиение таблиц бывает двух видов - вертикальное разбиение и горизонтальное разбиение.
Вертикальное разбиение является процессом перемещения некоторых колонок таблицы в другую новую таблицу, которая имеет тот же первичный ключ, что и исходная таблица. Горизонтальное разбиение является процессом перемещения некоторых строк одной таблицы в другую новую таблицу, которая имеет такую же внутреннюю структуру, что и исходная таблица.
Основные причины разбиения таблицы: либо существуют некоторые проблемы с производительностью запросов на этой таблице, либо непересекающиеся подмножества строк таблицы имеют значительное различие в производительности обработки. Т.е. подмножества строк таблицы редко встречаются в одном и том же запросе.
Вертикальное разбиение длинных строк
Проблемы с производительностью выполнения запросов на длинных строках таблицы являются наиболее частой причиной для выполнения вертикального разбиения таблицы. Критериями того, что строка является длинной, могут быть:
· длина строки больше, чем длина физической страницы базы данных (> 1 Кб);
· использование так называемого индекса хэширования (cluster hashed index).
Рассмотрим случай, когда длина строки больше размера физической страницы базы данных. Таблица в этом случае либо имеет слишком много колонок, либо некоторые колонки имеют большую длину. В этом случае СУБД при вставке строки в таблицу будет использовать одну или более дополнительных физических страниц для сохранения строки. Следовательно, при выборке строки из таблицы потребуется больше операций ввода/вывода на число дополнительных физических страниц. Производительность запроса при этом будет ухудшаться. Для увеличения производительности выборки можно разбить таблицу на одну или несколько таблиц с длиной строки подходящего размера.
Метод вертикального разбиения принципиально прост, если вспомнить, что разбиение эквивалентно реляционной операции проекции на таблице. Ясно, что некоторые колонки просто переносятся в новую таблицу так, чтобы длина оставшейся строки была подходящей (< 1 Кб). Разбиение не должно нарушать функциональных зависимостей между колонками. Поскольку мы предполагаем, что исходная таблица нормализована, в частности все неключевые колонки функционально полно зависят от первичного ключа, то первичный ключ новой таблицы является точной копией первичного ключа исходной таблицы.
Критичным вопросом является вопрос, какие колонки следует переносить в новую таблицу. При разбиении таблицы увеличение производительности будет достигаться только при раздельном доступе к полученным таблицам. При соединении полученных таблиц производительность такого запроса может быть ниже, чем с тем же запросом к исходной таблице из-за дополнительного ввода/вывода. Поэтому проектировщик данных, до того как принять решение о разбиении таблицы, должен проанализировать все транзакции к исходной таблице с высоким приоритетом и при разнесении колонок по таблицам руководствоваться принципом "частота совместного использования колонок в запросах, размещенных в каждой таблице разбиения, должна быть достаточно высока".
Пример. Обратимся к нашей учебной базе данных. Предположим, что в таблице EMPLOYEE необходимо дополнительно сохранять фотографию сотрудника и его автобиографию. Эти два новых поля имею достаточно большой размер, и длина строки таблицы заведомо превысит 1 Кб. Далее предположим, что существует 60 транзакций, которые обращаются к этой таблице. Только четыре из них обращаются ко всем колонкам: при вводе данных о сотруднике при приеме на работу, при внесении изменений, при удалении информации о сотруднике при его увольнении, и запрос руководителя, который имеет высокий приоритет. Все транзакции, кроме одной указанной выше, имеют средний и низкий приоритеты. Частота транзакции с высоким приоритетом ожидается не превышающей двух раз в неделю. Поэтому разбиение таблицы на две не сильно повлияет на производительность транзакций с высоким приоритетом в базе данных в целом.
Частота использования полей в транзакциях приведена в таблице 10.2.
Таблица 10.2. Частоты использования полей таблицы EMPLOYEE | |||
|
1. |
Номер личной карточки |
EMPNO (PK) |
60 |
|
2. |
Фамилия |
ENAME |
60 |
|
3. |
Имя |
LNAME |
50 |
|
4. |
Страховка |
SSECNO |
15 |
|
5. |
Номер подразделения |
DEPNO (FK) |
50 |
|
6. |
Должность |
JOB |
20 |
|
7. |
Возраст |
AGE |
4 |
|
8. |
Стаж |
HIREDATE |
4 |
|
9. |
Доплаты |
COMM |
50 |
|
10. |
Зарплата |
SAL |
50 |
|
11. |
Штрафы |
FINE |
50 |
|
12. |
Автобиография |
Biog |
4 |
|
13. |
Фотография |
Foto |
4 |
Данная таблица не содержит частоты совместного использования колонок в транзакциях, но из частот использования полей в транзакциях можно сделать вывод о совместном использовании колонок. Вероятнее всего, колонки, имеющие близкие значения частот использования, используются и совместно.
Таким образом, проектировщик базы данных имеет основание для принятия решения о разбиении таблицы EMPLOYEE на две. Скажем, EMPLOYEE и EMP_ADD. Полученный фрагмент скрипта приведен ниже.
CREATE TABLE EMPLOYEE( EMPNO integer NOT NULL, ENAME char(25), LNAME char(10), DEPNO int, SSECNO char(10), JOB char(25), SAL dec(9,2), COMM dec(9,2), FINE dec(9,2), PRIMARY KEY (EMPNO)); CREATE TABLE EMP_ADD( EMPNO integer NOT NULL, AGE date, HIREDATE date NOT NULL WITH DEFAULT, BIOG varchar(254), FOTO long varchar,PRIMARY KEY (EMPNO)
);Длинные строки в таблицах хэширования
Во многих реляционных СУБД поддерживаются так называемые хэш-кластерные индексы (clustered hashed index). Такие объекты правильнее называть таблицами хэширования, а не индексами. Таблица хэширования представляет собой таблицу реляционной базы данных, доступ к строкам которой осуществляется с помощью преобразования ключа. Значения колонок, которые объявлены ключевыми, преобразуются в позиции строк таблицы (и при их вставке там и размещаются) - хэшируются. Такую функцию называют хэш-функцией. Ключ таблицы, который подвергается преобразованию, называется хэш-ключом. Данные, которые обрабатываются таким образом, размещаются в специальных таблицах, называемых еще хэш-кластерами или просто хэш-таблицами. В настоящем курсе предполагается, что проектировщику известны общие методы организации физического доступа к данным, поэтому мы не будем детально обсуждать вопрос, как устроены такие таблицы.
Отметим только, что хэширование является очень эффективным методом доступа по первичному ключу к записи за один доступ. Если значения ключа равномерно распределены, то в среднем это будет так. В противном случае производительность доступа будет резко падать из-за коллизий, т.е. случая, когда для двух различных значений первичного ключа хэш-функция дает одинаковые числа, т.е. позиции записи. В худшем случае придется просканировать всю таблицу, чтобы получить одну запись!
Несмотря на то, что построены динамические таблицы хэширования (изменяющие свой размер во время существования), в большинстве СУБД поддерживаются статические таблицы хэширования, размер которых определяется при их создании. В большинстве случаев таблица хэширования формируется случайным образом по отношению к порядку следования значений ключа, хотя известны функции преобразования ключа, которые поддерживают лексикографический порядок на значении ключа таблицы.
Хэш-индекс обычно применяется, если ключ полностью представлен в предложении WHERE и используется операция равенства для колонок ключа. Нас интересует проблема увеличения производительности в хэш-таблицах, когда длина строки превышает размер физической страницы на жестком диске. Чтобы лучше понять проблему, рассмотрим, как определяется хэш-таблица в SQL.
Такая таблица создается при помощи команды, например
CREATE CLUSTERED HASHES INDEX CHXNAME ON EMPLOYEE(EMPNO) SIZE 2000 ROWS;Предложение SIZE задает вероятное количество строк в индексе, а ROWS определяет число строк для хранения индекса. Размер можно задавать в блоках (BUCKETS). Таким образом, по значению первичного ключа адресуется блок, содержащий целое число строк, или строка, если ее размер сопоставим с размером физического блока. В последнем случае считается, что блок содержит одну строку.
Для таблицы хэширования определяется параметр "число строк на странице" (rows per page) или "кластеризация страницы" (page clustering), или коэффициент блокировки, равный
Как видно из определения таблицы хэширования, размер строки и размер физического блока должны быть согласованы. Проблема длинной строки в таблице хэширования состоит в том, что если строка занимает несколько блоков, то возрастает частота коллизий и вместо одного физического доступа для получения строки требуется 4-6, что уже сопоставимо с использованием индексов другого типа.
Цель разбиения таблицы хэширования состоит в том, чтобы попытаться достигнуть такого значения параметра blocking factor (коэффициент блокировки), которое содержало бы по крайней мере как можно больше строк, которые будут выбираться вместе в большинстве транзакций к этой таблице в базе данных.
Поскольку в современных СУБД размер физического блока фиксирован для каждой операционной платформы, то единственным способом влияния на величину этого параметра является подгонка размера строки. Если нельзя пересмотреть спецификацию типов колонок таблицы и свести их размеры до минимума, то единственной возможностью выбрать подходящий коэффициент блокирования является разбиение таблицы хэширования.
Горизонтальное разбиение таблиц
На практике горизонтальное разбиение применяется для изоляции одной группы строк таблицы от другой, когда такие группы строк редко используются в одной транзакции. Наиболее типичный пример, когда этот метод оказывается полезным, есть изоляция текущих данных от архивных данных. Рассмотрим систему обработки заказов. Менеджеры и продавцы работают с текущими заказами. Обработка выполненных заказов (архивные данные) выполняется при подготовке разного рода отчетов. Даже если готовится ежедневный отчет с использованием архивных данных, то в организациях среднего размера частота использования текущих данных все равно превышает частоту использования архивных данных на 2-3 порядка, а отношение объема текущих данных к архивным данным может составлять менее 0,001.
Одним из практических критериев в данном случае может служить классическое правило 80-20. Если активно работают с 20% данных, то, вероятнее всего, остальные 80% можно перенести в архивную таблицу.
Пример. Для нашей учебной базы данных таблицей - кандидатом на такое горизонтальное разбиение является таблица PROJECT, поскольку в ней имеются архивные данные - выполненные проекты. Предположим, что число выполненных проектов в год в организации где-то около 1000. Данные в таблице нужно хранить 10 лет (10000). Средняя продолжительность проекта равна 2 месяцам, т.е. число незавершенных проектов в каждый момент времени не превышает 200. Через 5 лет отношение числа текущих проектов к архивным проектам достигнет 0,04. Следовательно, проектировщик данных может рассмотреть вопрос о горизонтальном разбиении этой таблицы.
CREATE TABLE PROJECT ( PROJNO char(8) NOT NULL, PNAME char(25), BUDGET dec(9,2), PRIMARY KEY (PROJNO)); CREATE TABLE PROJECT_OLD ( PROJNO char(8) NOT NULL, PNAME char(25), BUDGET dec(9,2), PRIMARY KEY (PROJNO));А для совместного использования двух этих таблиц предусмотреть представление
CREATE VIEW ALL_PROJECTASSELECT * FROM PROJECTUNIONSELECT * FROM PROJECT_OLD;Замечание. Далее под исходной таблицей понимается и сама таблица, и то, что от нее осталось после разбиения.
Разбиение таблиц и ссылочная целостность
Если до разбиения таблица была нормализована, то первичные ключи будут идентичны для таблиц, полученных в результате разбиения. Следовательно, взаимосвязи новых таблиц с другими таблицами базы данных могут остаться такими же, как и с первоначальной таблицей. Однако проектировщик базы данных должен рассмотреть как действие правил удаления для исходной таблицы, так и участие новой таблицы в существующих взаимоотношениях ссылочной целостности, когда будет решать вопрос об определении поддержки ссылочной целостности в новых таблицах. В некоторых случаях может быть проще не определять ссылочную целостность вовсе, так как фактическое удаление строк из новой таблицы будет поддерживаться параллельно с исходной таблицей каким-либо программным способом в приложении базы данных.
Пример. Для нашей учебной базы данных для разрешения отношения "многие-ко-многим" между таблицами EMPLOYEE и PROJECT была введена связывающая таблица EMP_PRJ, которая имеет ограничения ссылочной целостности с таблицей PROJECT. Но у нас появилась еще таблица PROJECT_OLD.
Предположим, что для реализации проекта организация нанимает сотрудников на временной основе (на время выполнения проекта), и вопрос, кто, какие проекты и когда делал, мало интересует руководство организации. В этом случае взаимосвязь между исполнителями и проектами, которые уже завершены, не интересует руководство, и, следовательно, во внутренней схеме больше ничего менять не нужно. Однако если взаимосвязь между исполнителями и завершенными проектами должна отслеживаться (например, руководство будет изучать вопрос, кто, когда и какой проект делал), ее следует распространить и на таблицу PROJECT_OLD. Для этого достаточно внести ограничение внешнего ключа в таблицу EMP_PRJ, как показано ниже:
CREATE TABLE EMP_PRJ( EMPNO integer NOT NULL, PROJNO char(8) NOT NULL, WORKS number, PRIMARY KEY (EMPNO, PROJNO), FOREING KEY (EMPNO) REFERENCES EMPLOYEE, FOREING KEY (PROJNO) REFERENCES PROJECT, FOREING KEY (PROJNO) REFERENCES PROJECT_OLD);При разбиении таблицы, для которой были определены ограничения ссылочной целостности, можно также рассмотреть возможность поддержки ссылочной целостности установлением взаимосвязи "один-ко-одному" в сторону исходной таблицы от новой таблицы. В этом случае новая таблица будет иметь внешний ключ, идентичный первичному ключу таблицы. Если определено каскадное правило удаления для этого внешнего ключа, то СУБД будет автоматически удалять строки новой таблицы, когда соответствующая строка исходной таблицы будет удалена, хотя управление вставкой строк придется перенести в приложение базы данных.
Пример. Для нашего примера окончательный код может быть следующим:
CREATE TABLE PROJECT ( PROJNO char(8) NOT NULL, PNAME char(25), BUDGET dec(9,2), PRIMARY KEY (PROJNO));CREATE TABLE PROJECT_OLD ( PROJNO char(8) NOT NULL, PNAME char(25), BUDGET dec(9,2), PRIMARY KEY (PROJNO) FOREING KEY (PROJNO) REFERENCES PROJECT);CREATE TABLE EMP_PRJ( EMPNO integer NOT NULL, PROJNO char(8) NOT NULL, WORKS number, PRIMARY KEY (EMPNO, PROJNO), FOREING KEY (EMPNO) REFERENCES EMPLOYEE, FOREING KEY (PROJNO) REFERENCES PROJECT,);При принятии решения о разбиении таблицы следует придерживаться следующего алгоритма:
1. Определить, какие колонки исходной таблицы в какие новые таблицы будут перемещены.
2. Создать новые таблицы с первичным ключом, идентичным первичному ключу исходной таблицы.
3. Если СУБД будет управлять ссылочной целостностью для новых таблиц таким же образом, как и для исходной таблицы, в зависимости от ее статуса как дочерней таблицы во взаимосвязи, то вы должны добавить колонку внешнего ключа каждой родительской таблицы во взаимосвязи в новую таблицу, т.е. новая таблица должна содержать ограничение внешнего ключа, идентичное родительской таблице для каждой взаимосвязи.
или
Можно установить связь "один-ко-одному" между новой таблицей и исходной таблицей, определив внешний ключ обратно к исходной таблице тождественным первичному ключу.
4. Если СУБД будет управлять ссылочной целостностью для новых таблиц таким же образом, как и для исходной таблицы, в зависимости от ее статуса как родительской таблицы во взаимосвязи, то вы должны добавить внешний ключ в каждую дочернюю таблицу исходной таблицы, чтобы идентифицировать эту новую таблицу как дочернюю.
или
Если поступить, как в первой части пункта 3, то новые таблицы не следует объявлять как родительские в других взаимоотношениях. Исходная таблица поддерживает все взаимосвязи, в которых она выступает родителем.
5. Следует прописать для разработчиков приложений все команды INSERT для полученных в результате разбиения таблиц, или указать правила, которым должна следовать вставка строк в эти таблицы.
6. Следует изменить все представления, которые основывались на исходной таблице, и, если нужно, рассмотреть создание новых представлений для доступа к новым таблицам.